Søknadsbasen: verktøyet jeg ikke fant, så bygget selv
Et CV-verktøy og jobbsøker-tracker som startet som frustrasjon over eksisterende løsninger, og ble til et lite produkt jeg faktisk bruker selv.
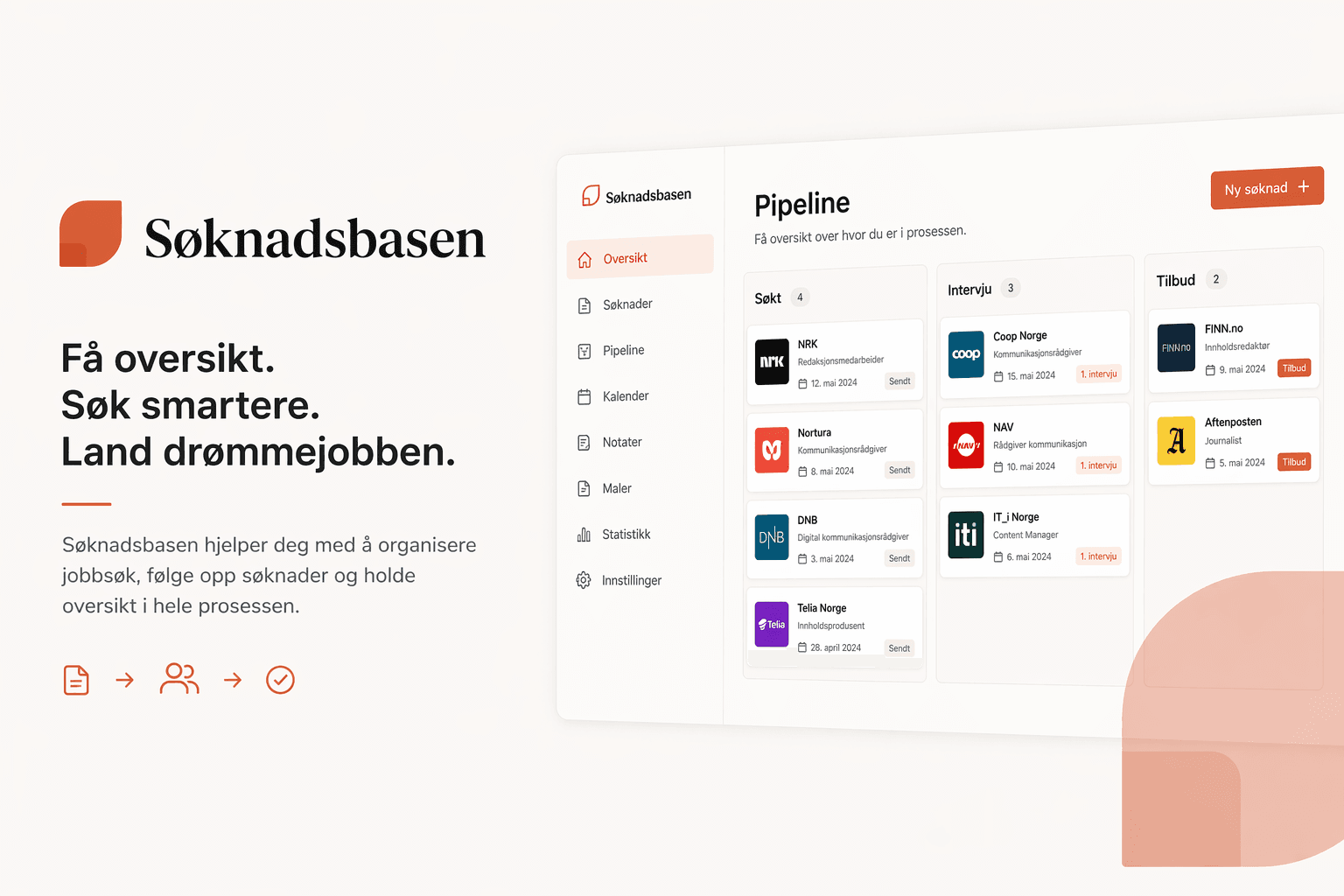
Søknadsbasen startet med irritasjon.
Jeg har søkt jobb et par ganger, og hver gang har jeg endt opp med samme rot: en mappe med halvferdige CV-filer, et regneark med søknadsstatus som er utdatert etter tre dager, og en liste med kontakter jeg ikke klarer å holde orden på. Det finnes mange verktøy for dette, men de fleste er enten for enkle til å være nyttige, eller så fulle av features at de krever en onboarding-prosess bare for å sende én søknad.
Jeg ville ha noe midt imellom. Noe jeg faktisk ville åpne.
Så jeg bygget det selv.
Problemet med eksisterende verktøy
De fleste jobbsøker-verktøy tenker på jobbsøking som en liste. Du legger inn en stilling, setter en status, kanskje noterer litt. Det er greit for de første ukene. Etter en måned med aktiv søking har du femti rader i den listen, og du har mistet konteksten på de fleste.
Det jeg manglet var en måte å tenke på jobbsøking som noe mer strukturert, en pågående prosess med faser, ikke bare et register over hva du har sendt inn.
Det jeg endte opp med å kalle "jobbsøk-sesjoner" var egentlig dette: at en jobbsøk-periode er sitt eget objekt i systemet. Den har en start, den har et mål, den har tilhørende søknader, og den har et utfall. Det lar deg se på én søknad i konteksten av hele perioden den tilhørte, ikke løsrevet fra alt annet.
Det høres kanskje komplisert ut, men det er intuitivt når du bruker det. Det er bare riktig abstraksjonsnivå for problemet.
Å bygge for deg selv er en annen øvelse
Jeg er vant til å bygge for klienter, eller for brukere jeg aldri møter. Det er en type disiplin: du må gjøre ting eksplisitt, du må skrive onboarding, du må hjelpe noen som ikke kan koden til å forstå hva knappen gjør.
Å bygge for meg selv åpnet for snarveier som var fristende og farlige på samme tid.
Den positive varianten: jeg trengte ikke bygge alt. Jeg trengte ikke en admin-panel for å redigere data, jeg kunne bare gå i databasen. Jeg trengte ikke en fancy onboarding-flyt, jeg visste allerede hvordan ting funket. Det sparte meg for mye tid på ting som ikke mattered.
Den negative varianten: jeg la for mye implisitt kunnskap inn i produktet. Funksjonalitet som gir mening for meg, men som ikke ville gitt mening for noen andre. Det er ikke et problem nå, men det er en begrensning hvis jeg noen gang vil la andre bruke det.
Leksjonen: bygg for deg selv med klar bevissthet om hva du ofrer av bredde. Det er et bevisst valg, ikke en bug.
CV-byggeren er den vanskeligste delen
En jobbsøker-tracker er egentlig bare en database med et grensesnitt. Det er ikke trivielt, men det er logisk.
En CV-bygger er noe helt annet.
CV-er har meninger om alt. Font-valg sender signaler om bransje og senioritet. Layout-hierarki påvirker hva rekrutterer ser i de første tre sekundene. Hva du inkluderer og hva du utelater er redaksjonelle valg, ikke bare innfylling av felter.
Jeg brukte mye mer tid på CV-delen enn jeg trodde. Ikke på teknisk implementasjon, men på å tenke gjennom hva et CV-verktøy faktisk skal hjelpe deg med. Er det å gjøre CV-en pyntelig? Er det å hjelpe deg velge hva du skal ta med? Er det å generere tekst?
Jeg landet på at det viktigste var kontroll og forutsigbarhet. Eksportert PDF skal se ut akkurat som forhåndsvisningen. Endringer skal reflekteres med én gang. Du skal aldri lure på om det du ser er det rekrutterer ser.
Det er lavere ambisjon enn "AI-generert CV tilpasset stillingen", men det er noe jeg faktisk stoler på.
Tekniske valg jeg er fornøyd med
Next.js og Supabase er defaultene mine nå, og de funket greit her også. Det er ikke spennende å skrive om, men det er poenget: default-valg som funker lar deg bruke energien på produktet, ikke på infrastruktur.
To valg jeg er spesielt fornøyd med:
Å modellere jobbsøk-sesjoner som første-klasses modell i skjemaet, ikke bare som et tag eller en status på søknaden. Det ga meg query-muligheter jeg ikke hadde tenkt over da jeg designet det, og det gjorde det naturlig å vise aggregert statistikk per sesjon.
Å la PDF-generering skje server-side. Jeg vurderte client-side PDF-generering lenge fordi det er enklere å sette opp. Men server-side gir konsistent rendering uavhengig av nettleser, og det er verdt kompleksiteten for noe som er kjernen i produktet.
Det jeg undervurderte
Filhåndtering er alltid mer komplisert enn det ser ut. Jeg ville la brukere laste opp profilbilde til CV-en, og jeg estimerte en halvtime på oppsett. Det tok en dag og tre omskrivinger, og jeg er fortsatt ikke hundre prosent fornøyd med flyten.
Det er ikke noe uvanlig i seg selv. Det som overrasket meg var at jeg undervurderte det selv etter å ha gjort det før. Noe med filhåndtering lar seg ikke fullt lære bort, det er noe du må møte på nytt i konteksten av akkurat dette prosjektet.
Jeg undervurderte også hvor mye tid jeg ville bruke på å designe selve CV-malen. Teknisk er det ikke vanskelig. Estetisk er det uendelig justerbart. Jeg satte meg en hard stopp-regel etter tredje iterasjon: dette er godt nok, ikke bra nok til å distrahere.
Hva jeg skulle gjort annerledes
Laget mer av admin-panelet tidligere. Jeg redigerte direkte i Supabase i starten, akkurat som jeg lærte av Klink-prosjektet, og glemte leksjonen likevel.
Bestemt meg for PDF-bibliotek på dag én. Jeg byttet mellom tre alternativer og mistet tid på hver overgang. Neste gang setter jeg meg ned og evaluerer ordentlig en gang, ikke itererer gjennom dem i produksjon.
Vært tydeligere på hva produktet ikke er. Uten den grensen er scope åpen i begge ender, og det er dyrt.
Hvorfor det var verdt det
Søknadsbasen er ikke et stort produkt. Det er et lite verktøy som hjelper én person, meg, å holde orden på noe som ellers skaper friksjon.
Men det var den første gangen jeg bygget noe jeg faktisk brukte aktivt mens jeg bygget det. Det gir en annen type feedback enn å se på analytics eller lese brukerrapporter. Du merker på kroppen når noe ikke funker bra nok, fordi du er frustrert av det selv.
Det er en luksus de fleste produktutviklere ikke har, å være sin egen mest kravstore bruker. Jeg prøver å ta vare på den leksjonen i andre prosjekter også: forstå brukerens frustrasjon så godt at du kjenner den selv.
Søknadsbasen lever på søknadsbasen.no. Den er ikke klar for allmenheten ennå, men det er dit det går.